@佛教经文分类Classification of Buddhist Verses
摘要
This study assesses the ability of machine learn-ing to classify verses from Buddhist texts into two categories: Therigatha and Theragatha, at-tributed to female and male authors, respec-tively. It highlights the difficulties in data pre-processing and the use of Transformer-based models on Devanagari script due to limited vo-cabulary, demonstrating that simple statistical models can be equally effective. The research suggests areas for future exploration, provides the dataset for further study, and acknowledges existing limitations and challenges.
- 研究目标:评估机器学习对Therigatha(女性作者)与Theragatha(男性作者)佛教经文的二分类能力
- 核心发现:
- 传统统计模型(SVC/朴素贝叶斯)AUC达0.88-0.89,优于所有Transformer模型
- Devanagari脚本因分词信息损失导致Transformer模型表现显著下降(AUC 0.76)
- 两类经文词汇重叠度仅10%,传统模型通过类别特有词汇即可有效分类
- 数据公开:提供1793节预处理经文数据集(GitHub: neveditsin/pali)
引言
研究背景
- 文本特性:
- Gatha为双行诗体,现存最早记载见于阿维斯塔经(公元前224-651年)
- 巴利语背景:研究文本(Theragatha和Therigatha)使用巴利语,这是一种与佛陀时代俗语(Prakrit)混合的语言,反映了早期佛教传播的语言特征。
- 作者争议:
- 32% Therigatha经文存在作者归属争议(Findly, 1999)
- 主题差异:Therigatha侧重苦难克服与社会约束(Blackstone, 2013)
相关工作
1. 多语言诗歌分类研究
- 英语诗歌分类: Kao和Jurafsky(2012)通过逻辑回归模型,提取风格特征(如用词、音韵、情感)区分专业诗人与业余创作者,验证了诗歌分类的可行性。
- 印地语诗歌分类: Pal和Patel(2020)使用朴素贝叶斯、随机森林等传统模型,在印地语诗歌分类中仅达64%准确率,凸显形态复杂语言(如印欧语系)的分类挑战。
2. 低资源语言文本分类方法
- 跨语言模型 vs. 传统模型:
- 优势案例:Li等(2020)的AgglutiFiT模型(基于XLM-R微调)在低资源语言分类中显著优于传统模型;Alekseev等(2024)在吉尔吉斯语任务中验证了XLM-Roberta的优势。
- 劣势案例:Lalthangmawii和Singh(2023)发现SVM在米佐语情感分类中与XLM-Roberta表现相当(75%准确率),表明模型选择需结合语言特性。
- 机器翻译辅助: Kumar等(2024)利用谷歌翻译生成低资源印度语数据集,LSTM模型有效捕捉情感特征
3. 巴利文本计算分析
- 语言复杂性: Zigmond(2021)通过k-means聚类和PCA,揭示巴利藏经中早期文本(律藏、经藏)与后期论藏的结构差异,指出巴利语的词形屈折、复合词对NLP工具的挑战。
数据集与预处理
1. 数据来源与结构
- 佛典出处:
数据源自巴利三藏(Tipitaka)的《小部》(Khuddaka-nikaya)中的《长老偈》(Theragatha)和《长老尼偈》(Therigatha),属于佛教经典中的“经藏”(Sutta-pitaka)。 - 章节划分:
- 按作者的诗句数量分章,如“Ekaka-nipaat”(单偈集)收录单人单偈,“Dukanipaat”(双偈集)收录单人双偈。
- Theragatha 含 21 章共 1288 偈,Therigatha 含 16 章共 524 偈,所有诗句按章节顺序编号。
2. 数据预处理
- 核心挑战:
- 标点符号标准化:不同scripts(天城文/罗马化)中标点符号的歧义性需统一处理规则。
- 文本补全(Peyaala 处理):
遇到“pe”(缩写标记,表示重复前文内容)时,需手动匹配上下文补全文本(因缺乏自动化工具)。 - 分词难题:
巴利语复合词(如“muni”与“munin”)的分割规则灵活,需保留原始形态以避免语义损失。
3. 数据统计与清洗
- 原始数据量:
Theragatha(1288 偈) vs. Therigatha(524 偈),总计 1812 偈。 - 清洗规则:
排除 19 条无法解决分词歧义的诗句(3 条来自 Therigatha,16 条来自 Theragatha),最终保留1793 条有效数据。 - 词汇分布:
| 统计指标 | 天城文 | 罗马化 |
|---|---|---|
| 总唯一词数 | 8787 | 8789 |
| 仅 Therigatha 独有词 | 2239 | 2242 |
| 仅 Theragatha 独有词 | 5642 | 5646 |
| 两类共有词 | 906 | 901 |
关键发现:两类偈颂的词汇重叠率仅约 10%(天城文 906/8787),暗示分类可能依赖“独有词”而非语义模式。
实验设计
1. 实验设置
- 任务定义:
二分类任务,类别为“M”(Theragatha,男性作者)和“F”(Therigatha,女性作者)。 - 数据划分:
按script类型(天城文/罗马)分别划分训练集(75%)和测试集(25%). - 评估指标:
综合使用ROC-AUC、MCC(马修斯相关系数)、F1值、平均精度(AP)等多指标。
2. 模型对比
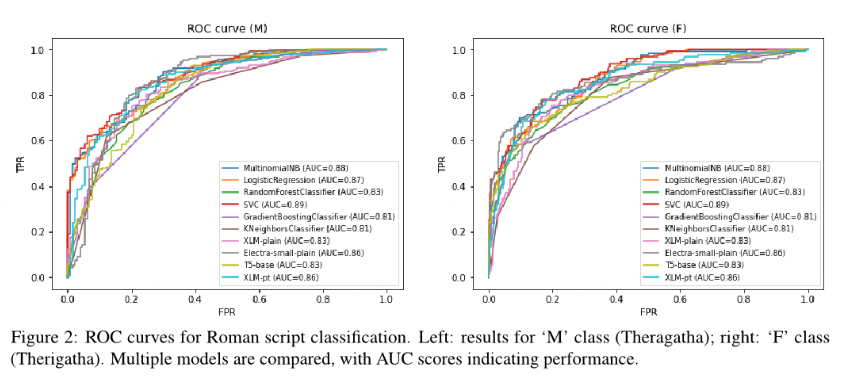
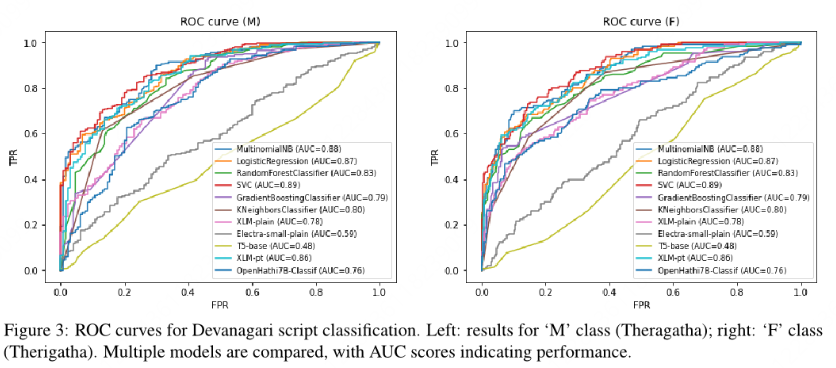
- 传统模型优势: SVM和朴素贝叶斯因依赖词频统计,在词汇独特性高的任务中表现稳定。
- 罗马化script更适配现有NLP工具,天城文因tokenizer词汇覆盖不足导致Transformer性能下降(如XLM AUC从0.83降至0.78)。